
我們已經知道如何訓練 Face recognition 的模型了!但我們都知道要一個好的模型應該要很多資料才行,在人臉辨識領域中也不例外,擁有高質量的大量訓練資料集是取得優越性能的關鍵。今晚我們就要來介紹 Dataset 這個主題!我們將討論人臉辨識資料集的收集、數量與品質的影響,以及清理資料的方法。
在想到資料集的時候,根據過去的經驗像是前幾章的內容,大家是不是會立刻想到使用公開資料集(Opendatasets)?沒錯在 Face recognition這個領域我們依樣也是有大量的人臉資料集可以使用!並且大家想一下人臉辨識用的資料集是不是只需要照片(如果照片範圍太大可能需要加上人臉位置方便專注在人臉區域)跟ID標記?因此其實人臉資料集相較於其他人臉應用(Facial landmark, EyeGaze, etc.)的資料集在建構上其實容易許多,那我們舉幾個非常知名的給大家示例:
A.Labeled Faces in the Wild (LFW):
* 簡介: LFW 是一個常用的人臉辨識資料集,擁有多個來自互聯網的人臉圖像。
* 特點: 包含超過13,000張圖像,每張圖像都有標註的人臉區域和身份信息。
* 用途: 主要用於人臉辨識算法的驗證(Face verification)和性能評估。
B.CelebA
* 簡介: CelebA 包含大約20萬張名人的圖像,擁有多個標籤,如性別、年齡、和表情。
* 特點: 由於擁有豐富的標籤資訊,CelebA也被用於人臉屬性分析和多任務學習。
* 用途: 常用於研究人臉屬性預測以及多標籤分類。

C.MegaFace
* 簡介: MegaFace 是一個大規模的人臉辨識挑戰,包含數百萬個來自網路的人臉圖像。
* 特點: 旨在測試模型在極大規模資料集上的性能,其中包含了挑戰性的情境,如跨年齡、跨種族的識別。
* 用途: 主要用於評估人臉辨識模型的穩定性和泛化性。

這些開放資料集提供了豐富的數據,可以用於不同層面的人臉辨識研究。在使用這些資料集時,應該仔細閱讀相關的文檔,了解資料集的特性、標籤的定義,以及可能的挑戰。此外,這些資料集的使用應遵守相應的許可和使用協議。
但有時候這些公開資料集並不是非常符合自己想要的資料分布,例如你可能想要戴墨鏡的照片多一點或者長捲髮的人多一點?如果可能,你會想要建立自有的資料集,這樣你可以確保資料符合你特定的應用場景。那要如何去做呢?自己去找身邊的人但數來數去就一兩百人,能想得到可能大都是同一種風格(ex.青少年 or 社會人士,難跨年紀)、人種的朋友。
主要我們會遇到的議題為:
Q1.要收集誰的照片?
Q2.要去哪裡如何有效率的收集照片?
Q3.收集的照片可不可以變化非常多樣?
那以上這三個問題其實我們恰恰好可以用一個族群的的照片來解決,那就是(電影)明星的照片!接下來我們來介紹如何透過 IMDB網站去抓取收集成我們自己的資料集:
Step.1 登入IMDB網站
Step.2 搜尋有興趣的明星名字,這裡舞們舉例用 Johnny Depp
Step.3 按下搜尋完之後跳到 Johnny Depp 頁面然後按下 "PHOTO" 按鍵

Step.4 接著你就會看到個是屬於這個明星的照片了!可以直接下載或者寫個爬蟲去撈
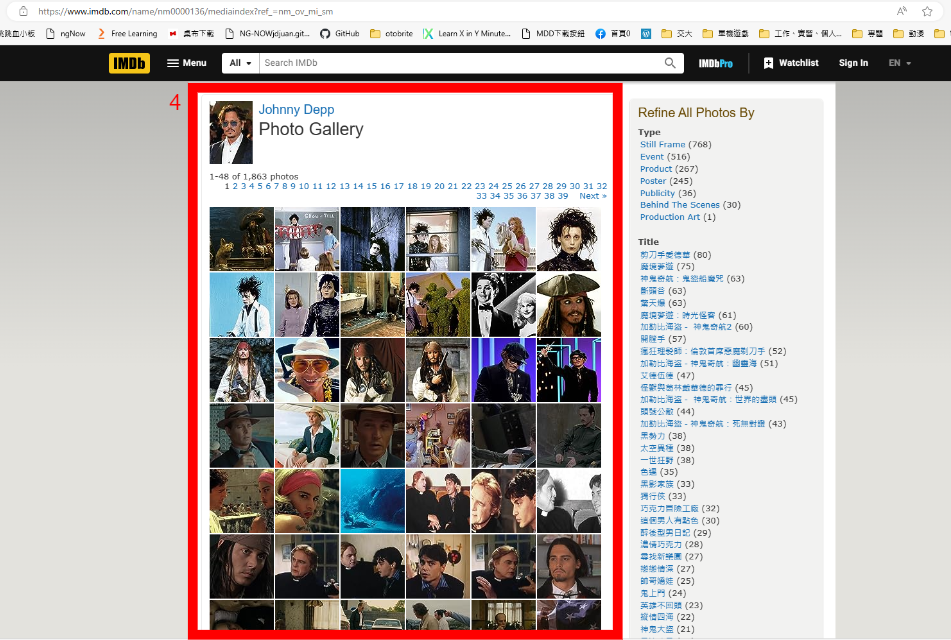
以上就是一個簡單有細的抓取建構 Face recognition datasets 的方法,IMDB-Face 也是基於這樣的方法去建構的喔!
那資料集的質量跟數量是否會影響模型學習的結果呢?我們直覺上應該會覺得一定有關係呀,像是資料集越多應該會越好吧,但感覺資料集同時又不能太髒(ex.ID 標記錯一堆這樣資料就算多對模型訓練應該也不好),而實務上確實也是,我們從最新最大的開源Face recognition dataset -- Webface260M 的論文 幫我們整理的結果來看:
資料集的數量對於深度學習模型的表現至關重要。更多的資料通常能夠提高模型的泛化性能。例如下圖比較: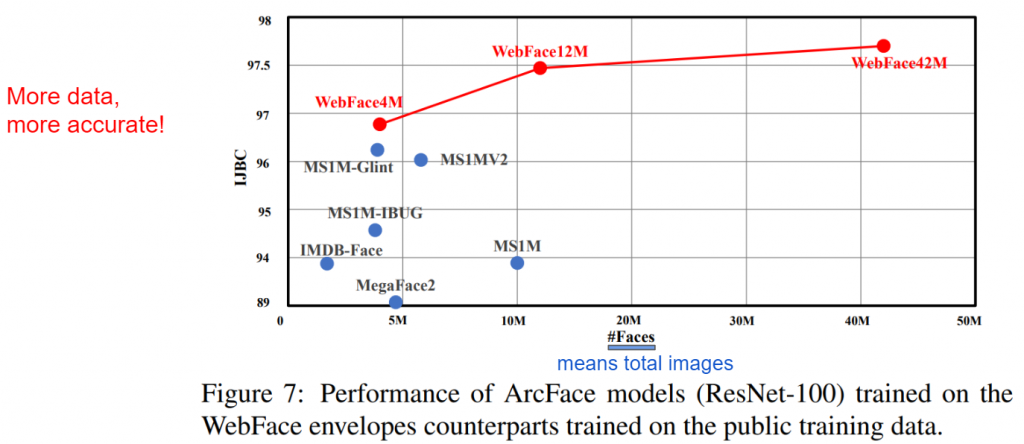
這個實驗是比較同一個 Face recognition model (Backbone為 resnet 而 Large marginal head 為 Arcface,詳細實作可參考昨天章節) 在使用不同資料集去做訓練最後測試在IJB-C這個有名的人臉辨識 benchmark,並且附上Y軸為 Accuracy,X 軸為資料集中內含的照片(人臉)數 。我們可以輕易看出:
隨著資料集的變大,準確度有上升的趨勢!
而學界一直以來確實也有這個共識,因此我們可以看到歷年來釋出的資料集是越來越大,並且請留意** FB(現為 Meta) & Google 等大公司其實在 2014、2015年就已經掌握了非常龐大的資料集了!**擁有大的資料集確實為 Face recognition 技術競爭力的一大前提!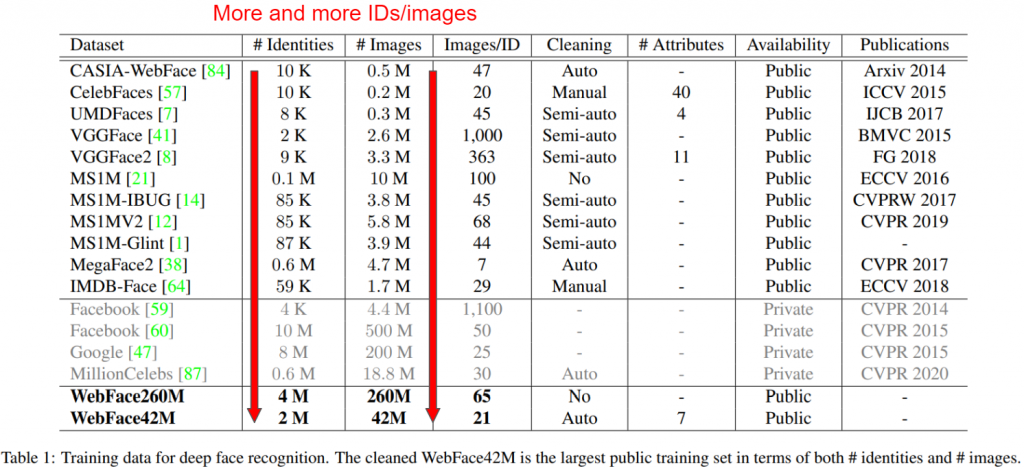
另外筆者也提一個大資料集除了資料變多理論可以訓練更好這個直觀想法外的解釋:
越多人(ID)在訓練資料集裡面是不是可以想成
Open-set的比較可能越接近成為Close-set,因此測試難度就會降低!
所以我們可以看到除了照片(人臉)的數量在上升,其實 ID 的數量大家也是追求越多越好的趨勢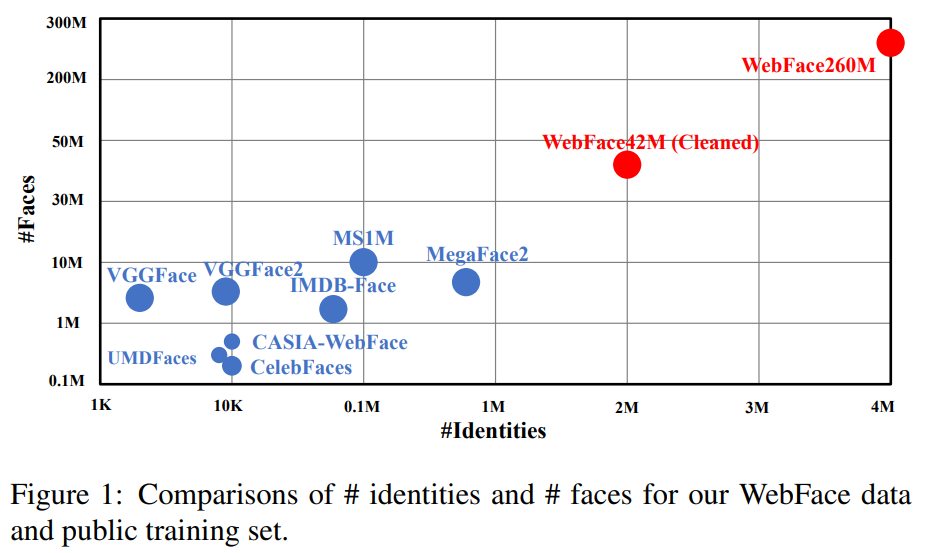
但只有數量就可以解決一切了嗎?理論上資料品質包括圖像的解析度、標籤的正確性、以及圖像中人臉的多樣性。高品質的資料集能夠幫助模型更好地學習特徵。於是我們一樣觀察一下大家這幾年的大家資料集追求的東西,確實發現除了照片數以及ID數逐年上升,在清理 dataset的技術在各個論文的發展趨勢中其實逐年要求: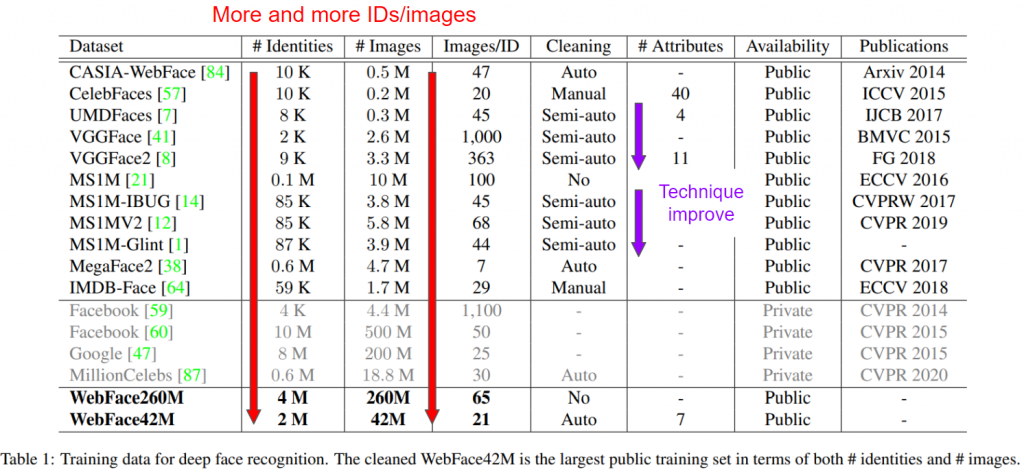
我們可以看到資料清潔(data cleaning)的方法一共有好幾種,從完全不管的"No"到直接讓人工來挑圖的"Manual"都有。效果上 Semi-auto 以及 Auto 則要看演算法本身的效果(但越近期的同類型演算法應該是越強, ex.Semi-auto,~不然論文怎麼發><~ )但無可否認的是 Manual基本上就是清得最乾淨的一種(~都是用錢換出來的~)
可資料的清潔(data cleaning)效果又會影響訓練效果多少呢?我們一樣回到資料集大小與測試在IJB-C表現的比較,但我們把資料清理(data cleaning)的方法一同標上去觀察: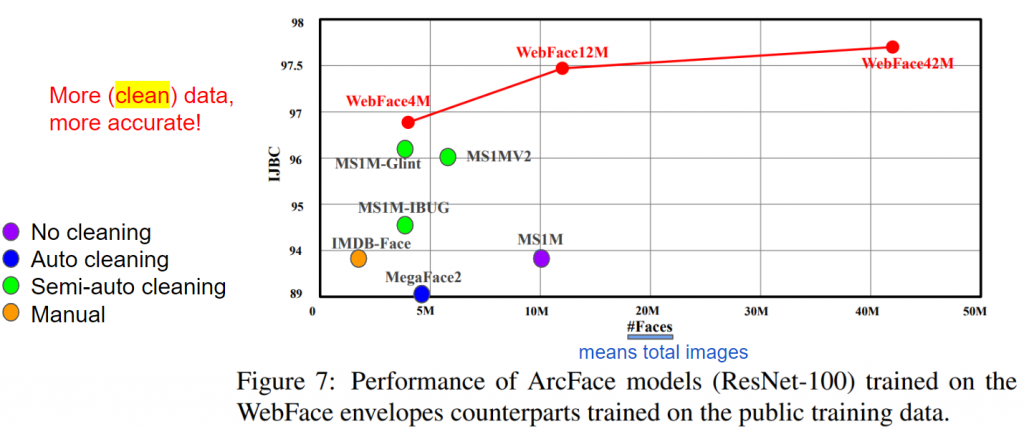
這樣一來我們其實可以清楚的看出數量並不是絕對的優勢,有做好清理得也非常重要,像是:
Manual清理出來的IMDB-Face可以大幅超越較大的但清得比較不乾淨(Auto-cleaning)的MegaFace2資料集。甚至Manual清理出來的IMDB-Face與超大但完全沒有清理的MS1M資料集的效果齊平
data cleaning)的方法我們首先來看看前面講到的從網路上拿到的資料可能有甚麼問題,我們以上面找到的Johnny Depp照片來說: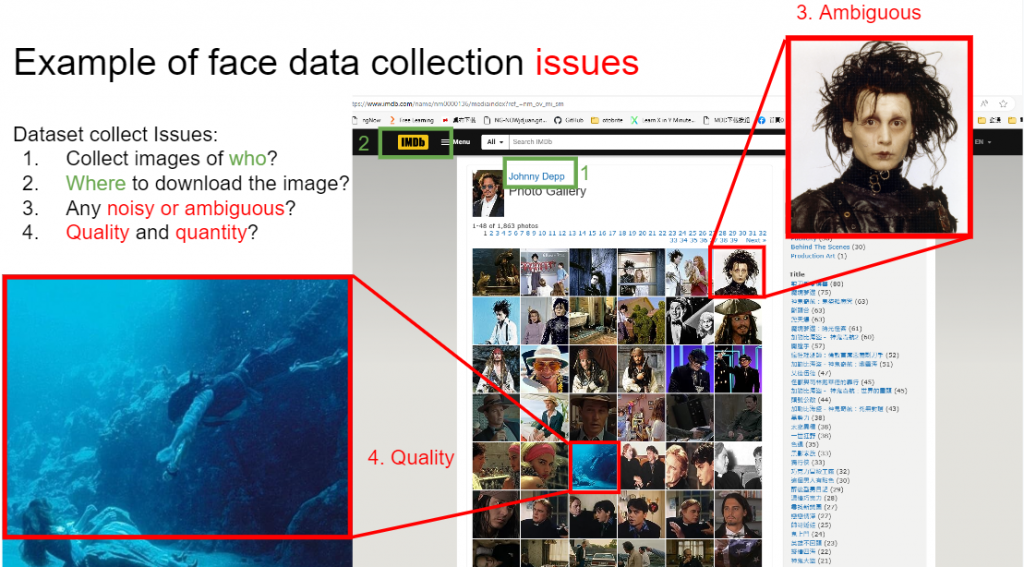
我們可以看到我們雖然成功解決 "要收集誰的照片" 以及 "去哪收集照片" 這兩件事,但我們卻遇到了 "可能/雜訊太大/誤導&標記錯誤(noisy label)/困惑的照片(如圖片中"3")" 以及 "畫質不夠清楚(如圖片中"4")" 這兩件頭痛的事。而這樣的資料舞們大概都能夠理解實在不利於模型學習,於是資料清理(data cleaning)方法就是要將這些照片剔除出去!
data cleaning)的目標資料清理(data cleaning)的目標其實有以下四種,但我們以A. 异常值檢測為最緊急的任務!
A. 异常值檢測
檢測和處理資料集中的異常值,這可能是由於錯誤標記或圖像質量問題引起的。
B. 重複樣本處理
檢測和刪除重複的樣本,以確保資料集的多樣性。
C. 不平衡類別處理
處理資料集中不平衡的類別,這可以通過欠採樣、過採樣或使用權重來實現。
D. 圖像質量改進
使用圖像處理技術,如去噪、對比度增強等,來提升圖像質量。
data cleaning)的方法分類從上面的小節--資料集數量和品質的影響中提到的表,可以看到資料的清理(data cleaning)大概有以下幾種分類:
A. No cleaning : 從網上收集完直接用,全靠模型訓練演算法(像是Robust training, ex.Co-teaching),~真。勇者~
B. Auto cleaning : 大致為 cluster 或者使用圖片分析(也可能使用 model 去分析)去掉,近期知名的為 Self-Training/Teacher-Student 的方法,像是 Webface260M 中的資料清理就屬於這一類
C. Semi-auto cleaning : 基於B. Auto cleaning 有加入人為處理部分,可視為Auto cleaning與Manual的混和體
D. Manual : 完全依照人為(~我看到人民勞動的血與汗~

那除去完全沒做 data cleaning 的 No cleaning 以及可視為Auto cleaning與Manual的混和體的Semi-auto cleaning,以下我們就針對Auto cleaning & Manual 來介紹人們是怎麼做:
Auto cleaning我們舉 Webface260M 提出的 Cleaning Automatically by Self-Training(CAST),流程如下圖: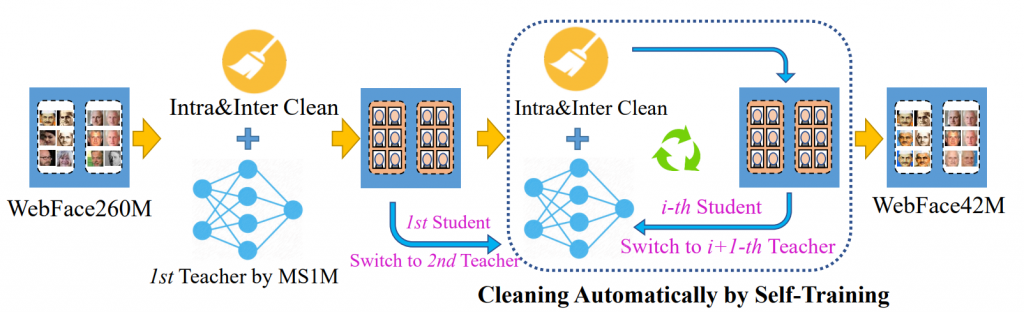
那其中Intra&Inter Clean具體流程我們簡單解釋如下:
Step.1.一開始分 N 個 Folder, 每個 Folder 裡面放一個臉
Step.2.用訓練好的 Face recognition Model (Teacher model)去算出 Feature, 並且觀察哪一些 Folder 的距離很近,很近就 merge 從而產生新的 dataset
Step.3.用新的 dataset 訓練新的 Face recognition model (Student model)回到步驟 2 (去當新的 Teacher model)直到新舊 Face recognition model converge
那效果也很明顯,隨者跑的次數越多, Noisy data 確實被分離了,如下圖: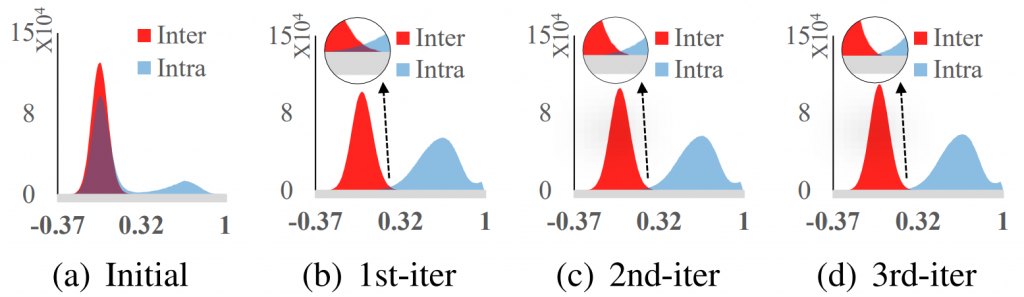
Manual既然要 Manual 了,那要怎麼樣 Manual呢?這一部份我們可以參考IMDB的作者當初在 ECCV2018 中提出的論文中提到的他們建構出了三種使用者介面去讓標記員來標記:
一共有三種標記:
a)幫忙標記人臉的位置,因為有些人臉如果使用訓練好的 Face detection model 去抓的話可能會抓錯或者抓歪,甚至一張圖有兩個人等其他非這個 ID 的人臉,他也是會抓到,但這樣就是 Noisy label 了
b)從很像的三張照片中去挑出與目標一樣的人
c)判斷是否為同一個人
以上這樣的系統我們可以架設起來讓標記原來標記,也可以放在 Amazon Mechanical Turk 上,對 Amazon Mechanical Turk有興趣的人可以看看這個 Amazon Mechanical Turk教學
建立一個優秀的人臉辨識模型開始於一個高品質的資料集。資料集的數量和品質直接影響模型的性能,而資料清理方法則確保模型訓練在高質量、多樣性且無誤的資料上。我們今晚與大家從資料集的收集方法、數據大小以及質量的影像到資料清裡的方法介紹了一遍,希望能讓大家對 Face recognition 的 dataset 議題更加了解!歡迎大家明晚再次回來~
1.Labeled Faces in the Wild (LFW)
2.CelebA
3.MegaFace
4.Wang, Fei, et al. "The devil of face recognition is in the noise." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
5.Zhu, Zheng, et al. "Webface260m: A benchmark unveiling the power of million-scale deep face recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
6.Brianna Maze, Jocelyn Adams, James A Duncan, Nathan Kalka, Tim Miller, Charles Otto, Anil K Jain, W Tyler Niggel, Janet Anderson, and Jordan Cheney. IARPA Janus Benchmark C: Face dataset and protocol. In ICB, 2018.
7.Guo, Yandong, et al. "Ms-celeb-1m: A dataset and benchmark for large-scale face recognition." Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14. Springer International Publishing, 2016.
8.Aaron Nech and Ira Kemelmacher-Shlizerman. Level playing field for million scale face recognition. In CVPR, 2017.
9.Han, Bo, et al. "Co-teaching: Robust training of deep neural networks with extremely noisy labels." Advances in neural information processing systems 31 (2018).
10.Amazon Mechanical Turk
11.Amazon Mechanical Turk教學

 iThome鐵人賽
iThome鐵人賽